If you’re on macOS and wanting to find out what system calls (syscalls) are being made by a process or application, you may have found that strace is not an option.
This is a quick post to demonstrate how to use DTrace to monitor system calls made by a process on macOS.
System Integrity Protection
First things first, you may find that newer mac systems have SIP (System Integrity Protection) enabled and that running dtruss will give you a warning about this. You’ll also likely not see much output at all.
It’s possible to disable this, but first be mindful of the security implications of disabling SIP, and second, be sure to set things back again once you’re done.
To disable SIP for DTrace, reboot your system into recovery mode (on my Apple M2 system I needed to shutdown completely, then power on, holding the button in until the recovery and startup options appeared).
Then I booted into the recovery tools, entered my usual user login, and used the menu bar at the top of the screen to open Utilities -> Terminal
Then ran:
csrutil enable --without dtrace
Tracing with DTrace/dtruss
dtruss is a DTrace version of truss, which is a Unix-specific command that prints out system calls made by a program.
We’ll use dtruss to see the syscalls made by a simple node application.
After this, a reboot back into the normal OS had me back at the terminal and ready to run dtruss.
Here’s a simple nodeJS program that we’ll trace.
const fs = require("fs");
const fd = fs.openSync("foo.txt", "r+");
fs.writeSync(fd, "foo", "utf8");
const test = fs.readFileSync("foo.txt");
console.log(test);
We load the fs module (used to make file operations), create a file descriptor pointing to existing file foo.txt in write mode, write the text “foo” to it, read it back by opening the file, and then write the result to stdout.
Let’s trace this program now.
sudo dtruss node example.js &> dtruss.log
Once that completes, you’ll see a lot of output detailing various system calls in the dtruss.log file. Much of this is made by the node environment itself, and a small part will be the actual example.js program. Scroll through until you find the part where the example.js script is loaded. It should start with
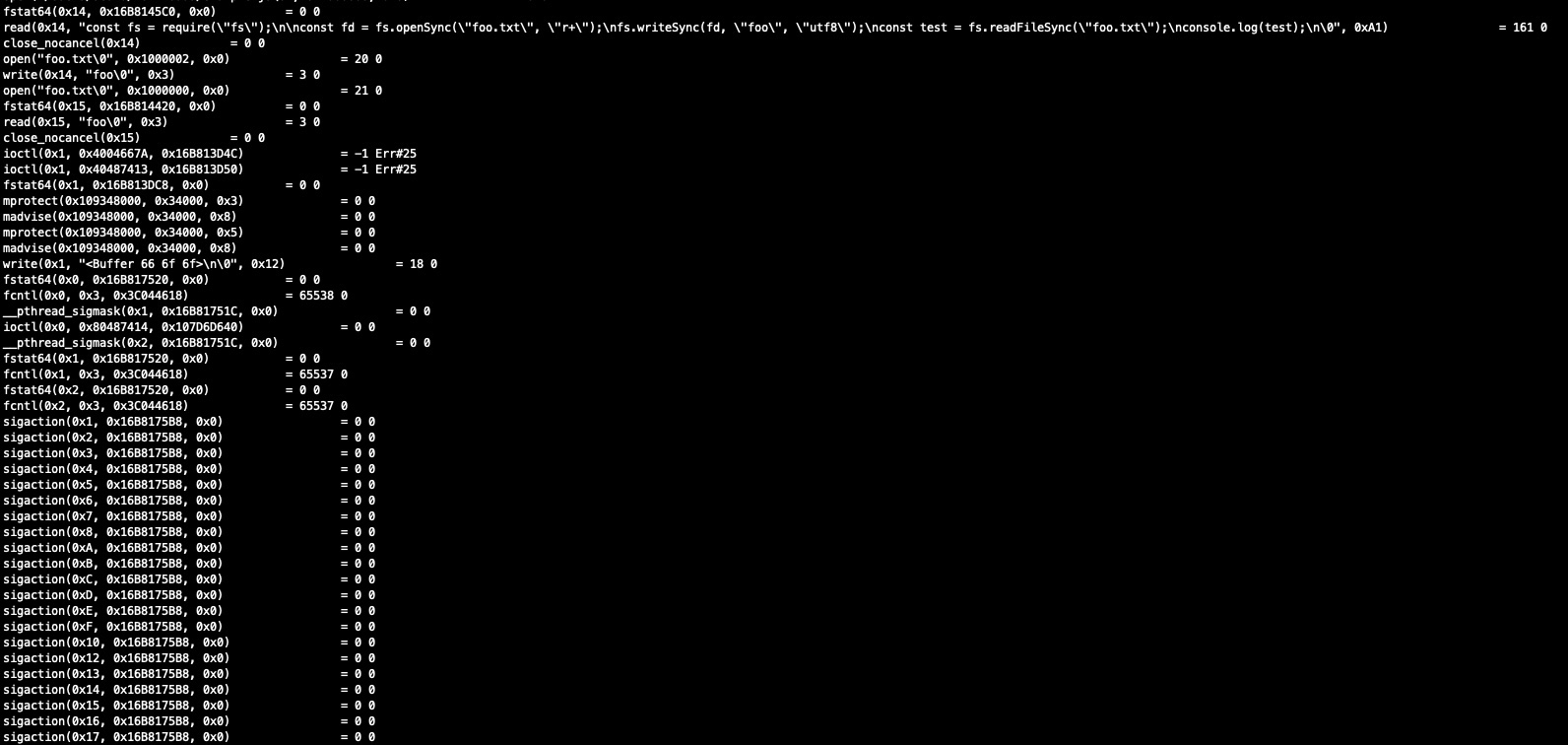
read(0x14, "const fs = require
Shortly after that you’ll see the syscalls made by the node program.
- open (to open foo.txt)
- write (to write the string ‘foo’ into the foo.txt file)
- open (to again open foo.txt and read the content)
- fstat64 which gets file status
- write (with Buffer containing hexadecimal value for foo 66 6f 6f) to write the value to stdout.
read(0x14, "const fs = require(\"fs\");\n\nconst fd = fs.openSync(\"foo.txt\", \"r+\");\nfs.writeSync(fd, \"foo\", \"utf8\");\nconst test = fs.readFileSync(\"foo.txt\");\nconsole.log(test);\n\0", 0xA1) = 161 0
close_nocancel(0x14) = 0 0
open("foo.txt\0", 0x1000002, 0x0) = 20 0
write(0x14, "foo\0", 0x3) = 3 0
open("foo.txt\0", 0x1000000, 0x0) = 21 0
fstat64(0x15, 0x16B814420, 0x0) = 0 0
read(0x15, "foo\0", 0x3) = 3 0
close_nocancel(0x15) = 0 0
ioctl(0x1, 0x4004667A, 0x16B813D4C) = -1 Err#25
ioctl(0x1, 0x40487413, 0x16B813D50) = -1 Err#25
fstat64(0x1, 0x16B813DC8, 0x0) = 0 0
mprotect(0x109348000, 0x34000, 0x3) = 0 0
madvise(0x109348000, 0x34000, 0x8) = 0 0
mprotect(0x109348000, 0x34000, 0x5) = 0 0
madvise(0x109348000, 0x34000, 0x8) = 0 0
write(0x1, "<Buffer 66 6f 6f>\n\0", 0x12) = 18 0
fstat64(0x0, 0x16B817520, 0x0) = 0 0
fcntl(0x0, 0x3, 0x3C044618) = 65538 0
__pthread_sigmask(0x1, 0x16B81751C, 0x0) = 0 0
ioctl(0x0, 0x80487414, 0x107D6D640) = 0 0
__pthread_sigmask(0x2, 0x16B81751C, 0x0) = 0 0
fstat64(0x1, 0x16B817520, 0x0) = 0 0
fcntl(0x1, 0x3, 0x3C044618) = 65537 0
fstat64(0x2, 0x16B817520, 0x0) = 0 0
fcntl(0x2, 0x3, 0x3C044618) = 65537 0
Finally, don’t forget to reboot into recovery mode and set SIP back to the default.