I’ve been constantly evolving my cloud backup strategies to find the ultimate cheap S3 cloud backup solution.
The reason for sticking to “S3” is because there are tons of cloud provided storage service implementations of the S3 API. Sticking to this means that one can generally use the same backup/restore scripts for just about any service.
The S3 client tooling available can of course be leveraged everywhere too (s3cmd, aws s3, etc…).
BackBlaze B2 gives you 10GB of storage free for a start. If you don’t have too much to backup you could get creative with lifecycle policies and stick within the 10GB free limit.
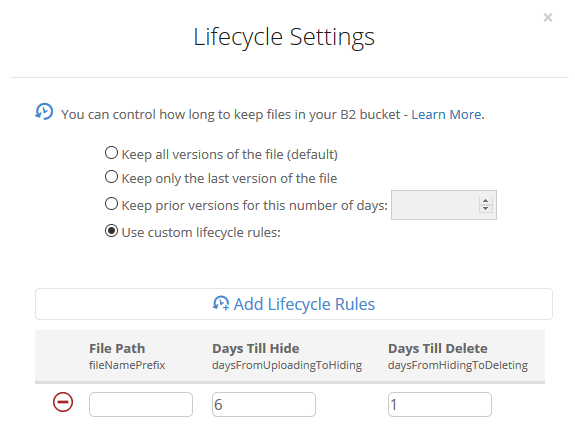
Current Backup Solution
This is the current solution I’ve setup.
I have a bunch of files on a FreeNAS storage server that I need to backup daily and send to the cloud.
I’ve setup a private BackBlaze B2 bucket and applied a lifecycle policy that removes any files older than 7 days. (See example screenshot above).
I leveraged a FreeBSD jail to install my S3 client (s3cmd) tooling, and mount my storage to that jail. You can follow the steps below if you would like to setup something similar:
Step-by-step setup guide
Create a new jail.
Enable VNET, DHCP, and Auto-start. Mount the FreeNAS storage path you’re interested in backing up as read-only to the jail.
The first step in a clean/base jail is to get s3cmd compiled and installed, as well as gpg for encryption support. You can use portsnap to get everything downloaded and ready for compilation.
portsnap fetch portsnap extract # skip this if you've already run extract before portsnap update cd /usr/ports/net/py-s3cmd/ make -DBATCH install clean # Note -DBATCH will take all the defaults for the compile process and prevent tons of pop-up dialogs asking to choose. If you don't want defaults then leave this bit off. # make install gpg for encryption support cd /usr/ports/security/gnupg/ && make -DBATCH install clean
The compile and install process takes a number of minutes. Once complete, you should be able to run s3cmd –configure to set up your defaults.
For BackBlaze you’ll need to configure s3cmd to use a specific endpoint for your region. Here is a page that describes the settings you’ll need in addition to your access / secret key.
After gpg was compiled and installed you should find it under the path /usr/local/bin/gpg, so you can use this for your s3cmd configuration too.
Double check s3cmd and gpg are installed with simple version checks.
gpg --version s3cmd --version
A simple backup shell script
Here is a quick and easy shell script to demonstrate compressing a directory path and all of it’s contents, then uploading it to a bucket with s3cmd.
DATESTAMP=$(date "+%Y-%m-%d") TIMESTAMP=$(date "+%Y-%m-%d-%H-%M-%S") tar --exclude='./some-optional-stuff-to-exclude' -zcvf "/root/$TIMESTAMP-backup.tgz" . s3cmd put "$TIMESTAMP-backup.tgz" "s3://your-bucket-name-goes-here/$DATESTAMP/$TIMESTAMP-backup.tgz"
Scheduling the backup script is an easy task with crontab. Run crontab -e and then set up your desired schedule. For example, daily at 25 minutes past 1 in the morning:
25 1 * * * /root/backup-script.sh
My home S3 backup evolution
I’ve gone from using Amazon S3, to Digital Ocean Spaces, to where I am now with BackBlaze B2. BackBlaze is definitely the cheapest option I’ve found so far.
Amazon S3 is overkill for simple home cloud backup solutions (in my opinion). You can change to use infrequent access or even glacier tiered storage to get the pricing down, but you’re still not going to beat BackBlaze on pure storage pricing.
Digital Ocean Spaces was nice for a short while, but they have an annoying minimum charge of $5 per month just to use Spaces. This rules it out for me as I was hunting for the absolute cheapest option.
BackBlaze currently has very cheap storage costs for B2. Just $0.005 per GB and only $0.01 per GB of download (only really needed if you want to restore some backup files of course).
Concluding
You can of course get more technical and coerce a willing friend/family member to host a private S3 compatible storage service for you like Minio, but I doubt many would want to go to that level of effort.
So, if you’re looking for a cheap S3 cloud backup solution with minimal maintenance overhead, definitely consider the above.
This is post #4 in my effort towards 100DaysToOffload.