I have been working on moving a collection of about 20-30 AWS accounts from two different AWS Organizations into a new AWS Organization with Control Tower enabled. During the process I have run into a number of different blockers and issues which have not always had the most obvious solutions due to cryptic errors that the AWS Control Tower enrollment process shows.
This blog post lists out some of the issues I have run into during account migrations, and what the underlying reasons and resolutions ended up being.
You can’t use the AWS IAM Identity Center provided user or account root user when enrolling accounts
If you login to the management account and try to enroll member accounts into AWS Control Tower, you’ll get a cryptic error in the AWS Console like:
An unknown error occurred. Try again later, or contact AWS Support. No launch paths found for resource: prod-xxxxxxxxxxxx
In my case, I was logged in initially with the AWS IAM Identity Center provisioned user account for the management account. This account is identified by the default Display Name of: AWS Control Tower Admin. The solution was to create a single IAM user with AdministratorAccess managed policy attached, then use the AWS Service Catalog console to add the user to the Portfolio Access on the AWS Control Tower Account Factory Portfolio item.
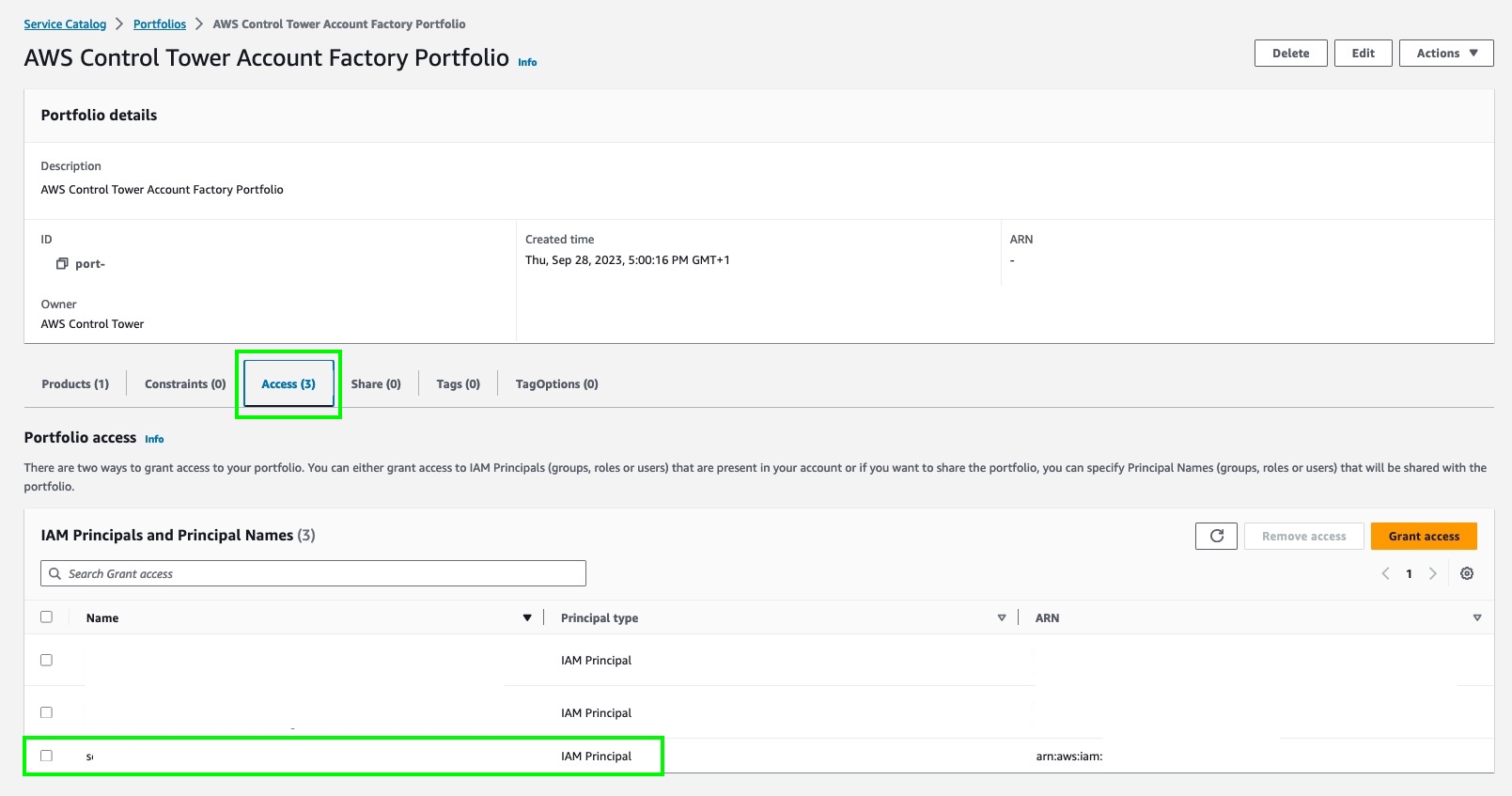
Once that was done, I could use the standard IAM user to login and successfully enroll member accounts into Control Tower.
In theory it should be possible to use the AWS IAM Identity Center provided user to enroll accounts into AWS Control Tower by ensuring it is added to the relevant Groups relating to provisioning and enrollment, but even after this I was unable to. Using a standard IAM user added to Portfolio access as above worked for me.
Forgetting to create the AWSControlTowerExecution IAM role in a member account before enrolling
Don’t forget to create the AWSControlTowerExecution IAM role with Principal ID access for the main Control Tower management account to assume during account enrollment.
This IAM role needs to be created before you can enroll accounts into AWS Control Tower. At a high level, it should be named AWSControlTowerExecution, it should have the AWS managed policy AdministratorAccess attached, and it should have a trust policy attached like the following:
{
"Version":"2012-10-17",
"Statement":[
{
"Effect":"Allow",
"Principal":{
"AWS": "arn:aws:iam::Management Account ID:root"
},
"Action": "sts:AssumeRole",
"Condition": {}
}
]
}
The process and role requirements are detailed in this AWS page.
AWS Config in existing accounts before enrolling them with AWS Control Tower
Here’s another issue that caught me out on one account. The account had it’s own AWS Config service Recorder and Delivery Channel setup (but it wasn’t actually being actively used).
When AWS Control Tower enrolls an account, it configures AWS Config with various best practices and configuration settings to record config changes. If there is existing AWS Config in the account, the enrollment process fails.
In my case I got the lovely error message:
I was scratching my head on this one until I decided to use the Update feature in the Control Tower console to try enrollment once more (where the account enrollment status showed Failed). The second time around, a clearer message was displayed:
AWS Control Tower could not enroll your account for the following reason: AWS Control Tower cannot create an AWS Config delivery channel because one already exists. To continue, delete the existing delivery channel and try again.
Trying to delete the AWS Config delivery channel was impossible though. AWS Control Tower applies guard rails via SCP, and because this account was partly enrolled, and now moved to an Organizational Unit (OU) that had SCPs attached to prevent AWS Config changes, it was impossible to remove the AWS Config settings that were blocking the enrollment process.
The fix was to ‘unmanage’ or un-enroll the AWS account (even though it wasn’t fully enrolled) using the AWS Control Tower console. Once that was done, and the account was moved back into the Organization root OU, I was able to use the AWS CLI to remove the offending AWS Config settings.
# find any delivery channels aws configservice describe-delivery-channels # describe delivery channel status aws configservice describe-delivery-channel-status # stop configuration recorder named 'default' (seen in describe above) aws configservice stop-configuration-recorder --configuration-recorder-name default # delete configuration recorder named 'default' aws configservice delete-configuration-recorder --configuration-recorder-name default
With the AWS Config preferences removed, the AWS Config console should show the initial ‘Set up AWS Config’ option – i.e. nothing is configured. At this stage it’s possible to enroll the account into Control Tower successfully.
Feature Photo by id23: https://www.pexels.com/photo/person-on-air-traffic-control-tower-10893728/