The saga pattern is useful when you have transactions that require a bunch of steps to complete successfully, with failure of steps requiring associated rollback processes to run. This post will cover the saga pattern with aws-cdk, leveraging AWS Step Functions and Lambda.
If you need an introduction to the saga pattern in an easy to understand format, I found this GOTO conference session by Caitie McCaffrey very informative.
Another useful resource with regard to the saga pattern and AWS Step Functions is this post over at theburningmonk.com.
Saga Pattern with aws-cdk
I’ll be taking things one step further by automating the setup and deployment of a sample app which uses the saga pattern with aws-cdk.
I’ve started using aws-cdk fairly frequently, but realise it has the issue of vendor lock-in. I found it nice to work with in the case of step functions particularly in the way you construct step chains.
Saga Pattern with Step Functions
So here is the step function state machine you’ll create using the fairly simple saga pattern aws-cdk app I’ve set up.
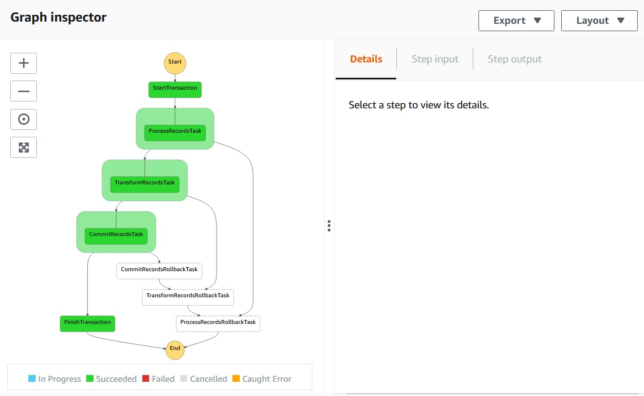
Above you see a successful transaction run, where all records are saved to a DynamoDB table entry.
If one of those steps were to fail, you need to manage the rollback process of your transaction from that step backwards.
Illustrating Failure Rollback
As mentioned above, with the saga pattern you’ll want to rollback any steps that have run from the point of failure backward.
The example app has three steps:
- Process Records
- Transform Records
- Commit Records
Each step is a simple lambda function that writes some data to a DynamoDB table with a primary partition key of TransactionId.
In the screenshot below, TransformRecords has a simulated failure, which causes the lambda function to throw an error.
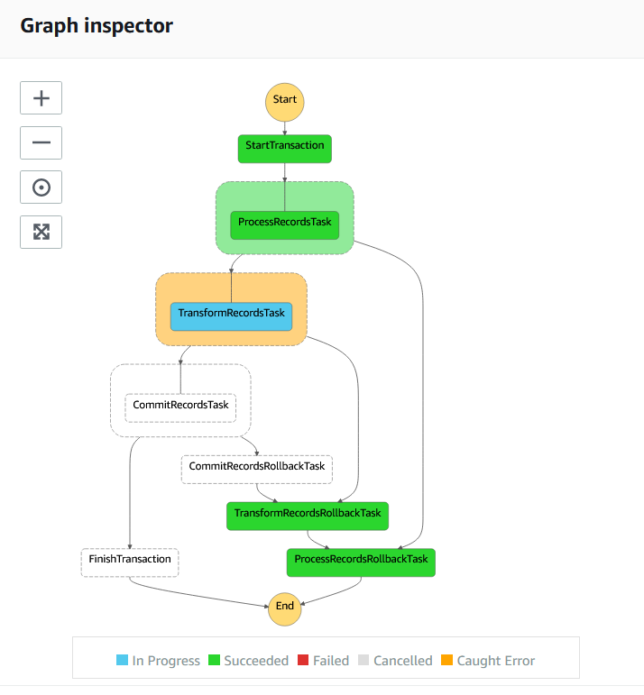
A catch step is linked to each of the process steps to handle rollback for each of them. Above, TransformRecordsRollbackTask is run when TransformRecordsTask fails.
The rollback steps cascade backward to the first ‘business logic’ step ProcessRecordsTask. Any steps that have run up to that point will therefore have their associated rollback tasks run.
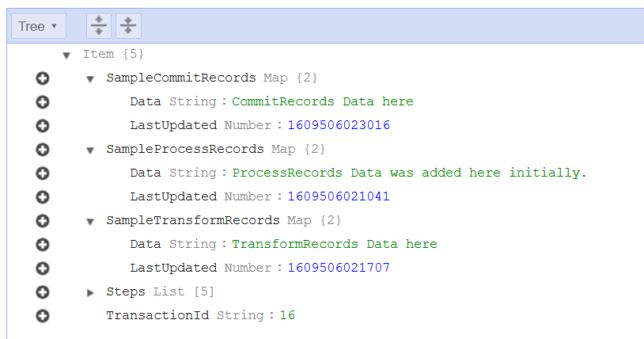
Here is what an entry looks like in DynamoDB if it failed:
You’ll notice this one does not have the ‘Sample’ data that you see in the previously shown successful transaction. In reality, for a brief moment it does have that sample data. As each rollback step is run, the associated data for that step is removed from the table entry, resulting in the above entry for TransactionId 18.
Deploying the Sample Saga Pattern App with aws-cdk
Clone the source code for the saga pattern aws-cdk app here.
You’ll need to npm install and typescript compile first. From the root of the project:
npm install && npm run build
Now you can deploy using aws-cdk.
# Check what you'll deploy / modify first with a diff cdk diff # Deploy cdk deploy
With the stack deployed, you’ll now have the following resources:
- Step Function / State Machine
- Various Lambda functions for transaction start, finish, the process steps, and each process rollback step.
- A DynamoDB table for the data
- IAM role(s) created for the above
Testing the Saga Pattern Sample App
To test, head over to the Step Functions AWS Console and navigate to the newly created SagaStateMachineExample state machine.
Click New Execution, and paste the following for the input:
{
"Payload": {
"TransactionDetails": {
"TransactionId": "1"
}
}
}
Click Start Execution.
In a few short moments, you should have a successful execution and you should see your transaction and sample data in DynamoDB.
Moving on, to simulate a random failure, try executing again, but this time with the following payload:
{
"Payload": {
"TransactionDetails": {
"TransactionId": "2",
"simulateFail": true
}
}
}
The lambda functions check the payload input for the simulateFail flag, and if found will do a Math.random() check to give chance of failure in one of the process steps.
Taking it Further
To take this example further, you’ll want to more carefully manage step outputs using Step Function ResultPath configuration. This will ensure that your steps don’t overwrite data in the state machine and that steps further down the line have access to the data that they need.
You’ll probably also want a step at the end of the line for the case of failure (which runs after all rollback steps have completed). This can handle notifications or other tasks that should run if a transaction fails.