
I picked up an nVidia RTX 3090 toward the end of last year. In hindsight, I was lucky to have purchased it early on soon after release. The GPU shortage has caused a massive spike in prices and this card is now worth double what I originally paid for it! Anyway, acquisition story aside, I was curious how it would perform in a Hashcat benchmark (all) run. Here are my Hashcat RTX 3090 benchmark results.
For a quick and easy run I’m using the hashcat 6.2.2 (Windows) binary.
.\hashcat.exe -b --benchmark-all
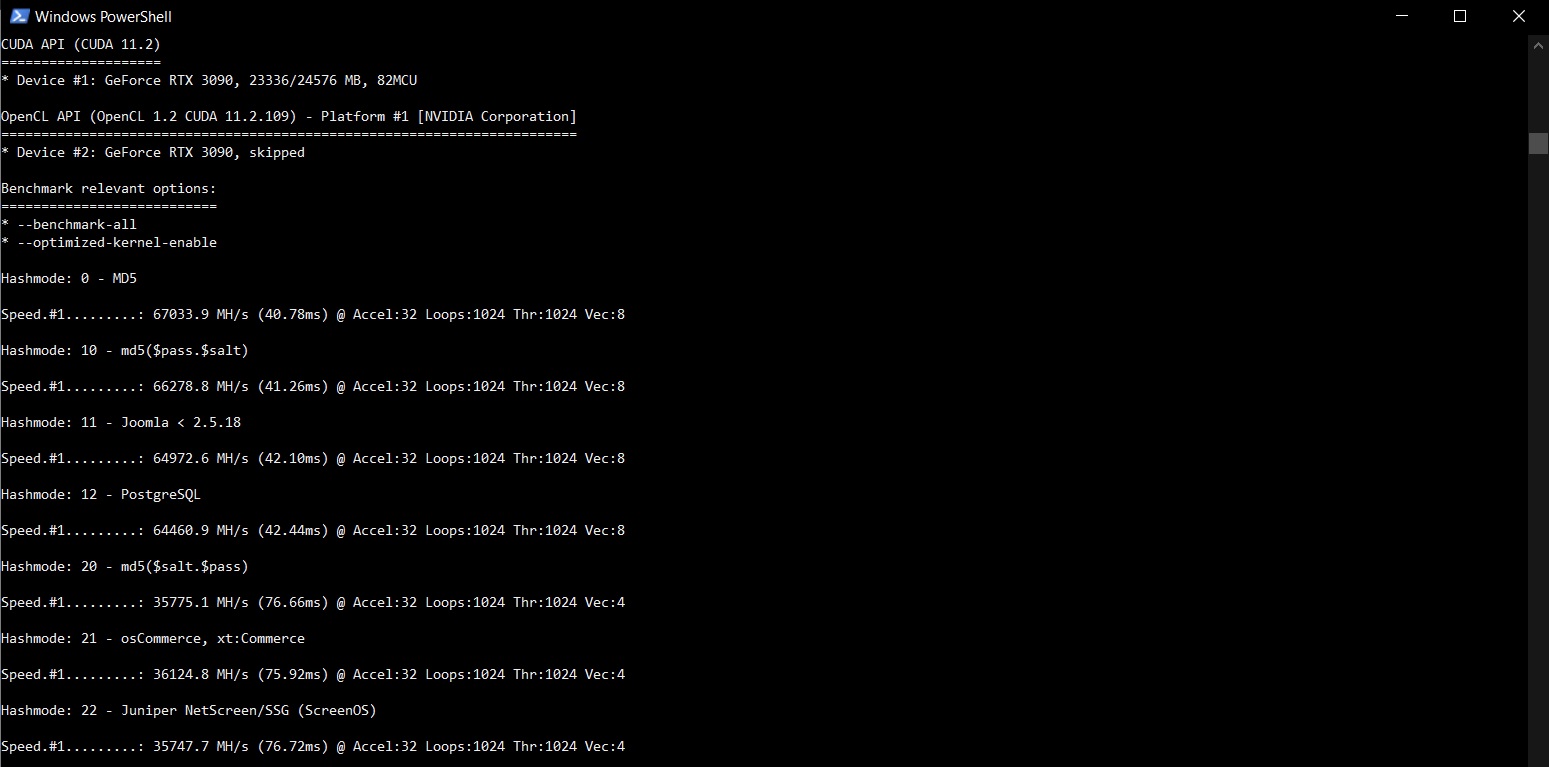
The performance seems on-par if not slightly higher than some other RTX 3090 benchmarks I have seen around. An impressive set of results.
I am running the MSI GeForce RTX 3090 Ventus 3X OC 24GB model card. I upgraded from a GeForce 1080 Ti (12GB) model and the hashing speeds are way faster. The 3090 is a power hungry beast though. It gets hot and the fans are noisier than my 1080 Ti’s were. To ensure my system’s power delivery was up to the task, I also upgraded to a Seasonic Focus PX-850 850W 80+ Platinum at the same time.
Here is a shortened log of my benchmark –all run:
CUDA API (CUDA 11.2) ==================== * Device #1: GeForce RTX 3090, 23336/24576 MB, 82MCU OpenCL API (OpenCL 1.2 CUDA 11.2.109) - Platform #1 [NVIDIA Corporation] ======================================================================== * Device #2: GeForce RTX 3090, skipped Benchmark relevant options: =========================== * --benchmark-all * --optimized-kernel-enable Hashmode: 0 - MD5 Speed.#1.........: 67033.9 MH/s (40.78ms) @ Accel:32 Loops:1024 Thr:1024 Vec:8 Hashmode: 10 - md5($pass.$salt) Speed.#1.........: 66278.8 MH/s (41.26ms) @ Accel:32 Loops:1024 Thr:1024 Vec:8 Hashmode: 11 - Joomla < 2.5.18 Speed.#1.........: 64972.6 MH/s (42.10ms) @ Accel:32 Loops:1024 Thr:1024 Vec:8 Hashmode: 12 - PostgreSQL Speed.#1.........: 64460.9 MH/s (42.44ms) @ Accel:32 Loops:1024 Thr:1024 Vec:8 Hashmode: 20 - md5($salt.$pass) Speed.#1.........: 35775.1 MH/s (76.66ms) @ Accel:32 Loops:1024 Thr:1024 Vec:4 Hashmode: 21 - osCommerce, xt:Commerce Speed.#1.........: 36124.8 MH/s (75.92ms) @ Accel:32 Loops:1024 Thr:1024 Vec:4 Hashmode: 22 - Juniper NetScreen/SSG (ScreenOS) Speed.#1.........: 35747.7 MH/s (76.72ms) @ Accel:32 Loops:1024 Thr:1024 Vec:4 Hashmode: 23 - Skype Speed.#1.........: 35632.9 MH/s (76.96ms) @ Accel:32 Loops:1024 Thr:1024 Vec:4 Hashmode: 24 - SolarWinds Serv-U Speed.#1.........: 35107.4 MH/s (78.12ms) @ Accel:32 Loops:1024 Thr:1024 Vec:1 Hashmode: 30 - md5(utf16le($pass).$salt) Speed.#1.........: 65511.3 MH/s (41.73ms) @ Accel:32 Loops:1024 Thr:1024 Vec:4 Hashmode: 40 - md5($salt.utf16le($pass)) Speed.#1.........: 36398.3 MH/s (75.35ms) @ Accel:32 Loops:1024 Thr:1024 Vec:4 Hashmode: 50 - HMAC-MD5 (key = $pass) Speed.#1.........: 10893.9 MH/s (62.90ms) @ Accel:8 Loops:1024 Thr:1024 Vec:1 Hashmode: 60 - HMAC-MD5 (key = $salt) Speed.#1.........: 22468.1 MH/s (60.99ms) @ Accel:32 Loops:512 Thr:1024 Vec:1 Hashmode: 70 - md5(utf16le($pass)) Speed.#1.........: 64396.2 MH/s (42.49ms) @ Accel:32 Loops:1024 Thr:1024 Vec:1 Hashmode: 100 - SHA1 Speed.#1.........: 21045.1 MH/s (65.11ms) @ Accel:16 Loops:1024 Thr:1024 Vec:1 Hashmode: 101 - nsldap, SHA-1(Base64), Netscape LDAP SHA Speed.#1.........: 20874.3 MH/s (65.66ms) @ Accel:16 Loops:1024 Thr:1024 Vec:1 Hashmode: 110 - sha1($pass.$salt) Speed.#1.........: 21217.0 MH/s (64.60ms) @ Accel:32 Loops:512 Thr:1024 Vec:1 Hashmode: 111 - nsldaps, SSHA-1(Base64), Netscape LDAP SSHA Speed.#1.........: 20608.3 MH/s (66.51ms) @ Accel:16 Loops:1024 Thr:1024 Vec:1
Full results can be downloaded here:
As for the PC build around the RTX 3090, here are a few photos…



You might notice an AIO installed, but not connected – I was in the process of testing a dual 240mm radiator (AIO) versus a high performing Noctua air cooler, so had left it in the chassis during transition.
I’ll see if I can run the same benchmark suite on my uBuntu install and update the results here. I have not tested the RTX 3090 card under this OS yet so I’m not sure if I’ll run into any driver issues or not.
Funny story of how I ended up with an RTX 3090 (it is a bit overkill!)…
Back in September or October of 2020 (I forget when the 3xxx series launch was), I had pre-ordered the MSI RTX 3080 at MSRP. I was 180 or so in the pre-order queue after months of already waiting. My queue position was barely changing week over week and I got impatient. I saw a handful of RTX 3090 cards come in stock at a local retailer and purchased one.
These cards would generally remain in stock for a few days due to everyone holding out for the much cheaper (at the time) RTX 3080 pre-order promises.
It was a lucky break for me, as those 3080 cards never came for most in that queue. GPU mining and GPU shortages made sure of that. Prices sky rocketed. Looking up this card now I see it costs almost double what I originally paid last year (if you can even get stock that is).
Now I just hope the card lasts at least a few years or more so I don’t ever have to worry about RMA and stock levels…







