You’ve got a SNS topic in Account A and you wish to subscribe a Lambda function to this topic in Account B.
Setting this up requires configuration on both account sides with resource-based permission policies being applied to SNS in one account and Lambda in the other.
In other words, you’ll need to setup the permissions for SNS and Lambda to allow both subscription and invocation.
Getting Started
You should already have your SNS topic in Account A and a suitable Lambda function subscriber in Account B. For example:
Account A Id: 5556667778 (SNS topic lives here)
Account B Id: 12345678901 (Lambda function lives here)
Configure SNS topic in Account A to allow Subscriptions from Account B
Use the AWS CLI to add a resource-based permission policy to the SNS topic (using it’s ARN). This will allow the Receive and Subscribe actions from Account B.
Configure the Lambda function in Account B to allow invocation from the SNS topic in Account A
Next, add a resource-based permission policy to your Lambda function in Account B. This policy will effectively allow the specific SNS topic in Account A to invoke the Lambda function.
It’s always good practice to follow the principle of least privilege (POLP). In this case you’re only allowing the specific SNS topic in one account to invoke the specific Lambda function you’re adding the policy to.
Subscribe the Lambda function in Account B to the SNS topic in Account A
Of course you’ll need to actually subscribe the Lambda function to the SNS topic. From Account B (where your Lambda function is setup), run the following command to subscribe it to the SNS topic in Account A.
In this post I’ll explain how I created an AWS EC2 Spot Instance Termination Simulator to run on any EC2 instance.
It can signal typical monitoring scripts, applications, interrupt handlers, and more, just like a real Spot Termination signal would do.
Back story
Looking around, there aren’t really any straight forward ways of testing this behaviour.
The obvious way is to change the price you bid for spot instances to the threshold of the current market price. This is so that if there is a slight increase in demand your spot instance(s) will be terminated.
The problem with that approach is of course that you can’t easily predict when the price will move, or by how much.
How EC2 Spot Instance Termination warnings work
When your spot instance bid price is surpassed by the current market price, a Termination Notice becomes available on one of the instance’s metadata endpoints. For example, http://169.254.169.254/latest/meta-data/spot/termination-time.
There is one other, newer endpoint at http://169.254.169.254/latest/meta-data/spot/instance-action that could also be used.
At this point the endpoint returns an HTTP 200 response. A timestamp of when a shutdown signal is going to be sent to your instance’s OS is also returned.
In the case of the newer endpoint, a JSON string is returned with an action and time. Usually the endpoint usually simply returns a 404 not found response.
The tools out there tend to monitor this endpoint to warn and action in case of a Spot Termination notice being received.
The two minute warning feature was added by Amazon back in 2015, announced in this blog post.
It runs as a DaemonSet (one container/pod on each node) in host networking mode. It then polls the EC2 metadata endpoint every ‘x’ number of seconds, watching for termination signals.
During polling, if one is found, it will send a kubectl drain command to it’s host node. Pods will move off to other nodes in the cluster.
Simulating Spot Instance Termination with a fake web service and some proxying
I created a simple web service/API that simply returns a 200 HTTP response on the same http://169.254.169.254/latest/meta-data/spot/termination-time endpoint.
This is the legacy endpoint that spot instance termination signals go to. However, there is another, newer one that AWS now recommend using instead.
The other endpoint is http://169.254.169.254/latest/meta-data/spot/instance-action. The web service will also send a response there as a JSON string with an action and time field.
All that needs to be done is to forward traffic from the metadata endpoint 169.254.169.254:80 to the custom web service.
Have a look at the code and Docker image at the following locations:
The code for the simple NodeJS web service / API is in GitHub here
Run the EC2 spot instance termination simulator endpoints
Identify a candidate EC2 instance that you don’t mind messing with.
Warning: the following steps will override the entire EC2 instance metadata service. No other metadata endpoints will work. This is because they’re not implemented in this web service.
Kubernetes
Deploy the docker container (a Kubernetes deployment / service manifest is in the git repository).
Ideally, create a nodeSelector / label up in the deployment manifest before you kubectl apply it. This is so you can get the pod to run on the specific node you want to test.
The service is a NodePort service, exposing the port on the host it runs on.
List the service and the pod (and find the kubernetes node the pod is running on):
kubectl get svc ec2-spot-termination-simulator
kubectl get pod spot-term-simulator-xxxxxx -o wide
Take note of the NodePort the service is listening on for the Kubernetes node. E.g. port 30626.
Docker
docker run -p 30626:80 -e PORT=80 shoganator/ec2-spot-termination-simulator
Proxying the EC2 metadata service
Perform some trickery to proxy traffic destined to 169.254.169.254 on port 80 to localhost (where the container runs). This is so that the fake service can take the place of the real one.
SSH onto the Kubernetes node and run:
sudo ifconfig lo:0 169.254.169.254 up
sudo socat TCP4-LISTEN:80,fork TCP4:127.0.0.1:30626
Create an alias for the localhost interface at 169.254.169.254, effectively taking over the EC2 metadata service and sending that to 127.0.0.1 instead.
Forward TCP port 80 traffic (usually destined to the EC2 metadata service) to 127.0.0.1 on the NodePort 30626. This is where the ec2-spot-termination-simulator pod is running on this host. Substitute this with the correct port in your case.
As a result, it should return a 200 OK response with a timestamp from the fake service. This is the same as the real one would.
Example
Looking at how the kube-spot-termination-notice-handler service works specifically:
This service runs as a DaemonSet, meaning one instance per host. The instance on the node you set the simualtor up on should immediately drain the node. The instance won’t actually be terminated as this was of course just a simulated termination.
Other scenarios
If you’re not running on Kubernetes and are using a different spot termination handler, don’t worry. The system you’re using to monitor the EC2 instance metadata endpoint should still take action at this point.
The proxied web service is now returning a legitimate looking termination time notice on http://169.254.169.254/latest/meta-data/spot/termination-time.
Looking to install the Weave Net CNI on AWS EKS / Kubernetes and remove the AWS CNI? Look no further. This guide will detail and demonstrate the process.
What this guide will cover
Removing AWS CNI plugin
Installing the Weave Net CNI on AWS EKS
Making sure your EC2 instances will work with Weave
Customising Weave Net CNI including custom pod overlay network ranges
Removing max-pods limit on your EKS worker nodes
Reconfiguring pods that don’t work after switching to Weave. (E.g. those that need to talk back to the EKS master nodes that do not get the Weave overlay network)
Want the Terraform source and test scripts to jump right in?
Otherwise, read on for step-by-step and more information…
There are a few guides floating around that detail how to install the Weave Net CNI plugin for Amazon Kubernetes clusters (EKS), however I’ve not seen them go into much detail.
Most tend to skip over some important steps and details when it comes to configuring weave and getting the pod networking functioning correctly.
There are also some important caveats that you should be aware of when replacing the AWS CNI Plugin with a different CNI, whether it be Weave, Calico, or any other.
Replacing CNI functionality
You should be 100% happy with what you’ll lose if completely replace the AWS CNI with another CNI. The AWS CNI has some very useful functionality such as:
Assigning IP addresses (via ENIs) to place pods directly into your VPC network
VPC flow logs that make sense
However, depending on your architecture and design decisions, as well as potential VPC network limitations, you may wish to opt out of the CNI that Amazon provides and instead use a different CNI that provides an overlay network with other functionality.
AWS CNI Limitations
One of the problems I have seen in VPCs is limited CIDR ranges, and therefore subnets that are carved up into smaller numbers of IP addresses.
The Amazon AWS CNI plugin is very IP address hungry and attaches multiple Secondary Private IP addresses to EKS worker nodes (EC2 instances) to provide pods in your cluster with directly assigned IPs.
This means that you can easily exhaust subnet IP addresses with just a few EKS worker nodes running.
This limitation also means that those who want high densities of pods running on worker nodes are in for a surprise. The IP address limit becomes an issue for maximum number of pods in these scenarios way before compute capacity becomes a problem.
This page shows the maximum number of ENI’s and Secondary IP addresses that can be used per EC2 instance: https://github.com/awslabs/amazon-eks-ami/blob/master/files/eni-max-pods.txt
Removing the AWS CNI plugin
Note: This process will involve you needing to replace your existing EKS worker nodes (if any) in the cluster after installing the Weave Net CNI.
Assuming you have a connection to your cluster already, the first thing to do is to remove the AWS CNI.
kubectl -n=kube-system delete daemonset aws-node
With that gone, your future EKS workers will no longer assign multiple Secondary IP addresses from your VPC subnets.
Installing CNI Genie
With the AWS CNI plugin removed, your pods won’t be able to get a network connection when starting up from this point onward.
Installing a basic deployment of CNI Genie is a quick way to get automatic CNI selection working for containers that start from this point on.
CNI genie has tons of other great features like allowing you to customise which CNI containers use when starting up and more.
For now, you’re just using it to allow containers to start-up and use the Weave Net overlay network by default.
Install CNI Genie. This manifest works with Kubernetes 1.12, 1.13, and 1.14 on EKS.
Next, get a Weave Net CNI yaml manifest file. Decide what overlay network IP Range you are going to be using and fill it in for the env.IPALLOC_RANGE query string parameter value in the code block below before making the curl request.
Note: the env.IPALLOC_RANGE query string param added is to specify you want a config with a custom CIDR range. This should be chosen specifically not to overlap with any network ranges shared with the VPC you’ll be deploying into.
In the example above I had a VPC and VPC peers that shared the CIDR block 10.0.0.0/8). Therefore I chose to use 192.168.0.0/16 for the Weave overlay network.
You should be aware of the network ranges you’re using and plan this out appropriately.
The config you now have as weave-cni.yaml will contain the environment variable IPALLOC_RANGE with the correct value that the weave pods will use to setup networking on the EKS Worker nodes.
Apply the weave Net CNI resources:
Note: This manifest is pre-created to use an overlay network range of 192.168.0.0/16
Note: Don’t expect things to change suddenly. The current EKS worker nodes will need to be rotated out (e.g. drain, terminate, wait for new to appear) in order for the IP addresses that the AWS CNI has kept warm/allocated to be released.
If you have any existing EKS workers running, drain them now and terminate/replace them with new workers. This includes the source/destination check change made previously.
kubectl get nodes
kubectl drain nodename --ignore-daemonsets
Remove max pod limits on nodes:
Your worker nodes by default have a limit set on how many pods they can schedule. The EKS AMI sets this based on EC2 type (and the max pods due to the usual ENI limitations / IP address limitations with the AWS CNI).
Check your max pod limits with:
kubectl get nodes -o yaml | grep pods
If you’re using the standard EKS optimized AMI (or a derivative of it) then you can simply pass an option to the bootstrap.sh script located in the image that setup the kubelet and joins the cluster. Set –use-max-pods false as an argument to the script.
For example, your autoscale group launch configuration might get the EC2 worker nodes to join the cluster using the bootstrap.sh script. You can update it like so:
If you’re using the EKS Terraform module you can simply pass in bootstrap-extra-args – this will automatically setup your worker node userdata templates with extra bootstrap arguments for the kubelet. See example here
Checking max-pods limit again after applying this change, you should see the previous pod limit (based on prior AWS CNI max pods for your instance type) removed now.
You’re almost running Weave Net CNI on AWS EKS, but first you need to roll out new worker nodes.
With the Weave Net CNI installed, the kubelet service updated and your EC2 source/destination checks disabled, you can rotate out your old EKS worker nodes, replacing them with the new nodes.
kubectl drain node --ignore-daemonsets
Once the new nodes come up and start scheduling pods, if everything went to plan you should see that new pods are using the Weave overlay network. E.g. 192.168.0.0/16.
A quick run-down on weave IP addresses and routes
If you get a shell to a worker node running the weave overlay network and do a listing of routes, you might see something like the following:
# ip route show
default via 10.254.109.129 dev eth0
10.254.109.128/26 dev eth0 proto kernel scope link src 10.254.109.133
169.254.169.254 dev eth0
192.168.0.0/16 dev weave proto kernel scope link src 192.168.192.0
This routing table shows two main interfaces in use. One from the host (EC2) instance network interfaces itself, eth0, and one from weave called weave.
When network packets are destined for the 10.254.109.128/26 address space, then traffic is routed down eth0.
If traffic on the host is destined for any address on 192.168.0.0/16, it will instead route via the weave interface ‘weave’ and the weave system will handle routing that traffic appropriately.
Otherwise if the traffic is destined for some public IP address out on the wider internet, it’ll go down the default route which is down the interface, eth0. This is a default gateway in the VPC subnet in this case – 10.254.109.129.
Finally, metadata URL traffic for 169.254.169.254 goes down the main host eth0 interface of course.
Caveats
For the most part everything should work great. Weave will route traffic between it’s overlay network and your worker node’s host network just fine.
However, some of your custom workloads or kubernetes tools might not like being on the new overlay network. For example they might need to talk to other Kubernetes nodes that do not run weave net.
This is now where the limitation of using a managed Kubernetes offering like EKS becomes a bit of a problem.
You can’t run weave on the Kubernetes master / API servers that are effectively the ‘managed’ control plane that AWS EKS hosts for you.
This means that your weave overlay network does not span the Kubernetes master nodes where the Kubernetes API runs.
If you have an application or container in the weave overlay network and the Kubernetes master node / API needs to talk to it, this won’t work.
One potential solution though is to use hostNetwork: true in your pod specification. However you should of course be aware of how this would affect your application and application security.
In my case, I was running metrics-server and it stopped working after it started using Weave. I found out that the Kubernetes API needs to talk to the metrics-server service and of course this won’t work in the overlay network.
Example EKS with Weave Net CNI cluster
You can use the source code I’ve uploaded here.
There are five simple steps to deploy this example EKS cluster in your own account.
Modify the example.tfvars file to fit your own parameters.
terraform plan -var-file="example.tfvars" -out="example.tfplan"
terraform apply "example.tfplan"
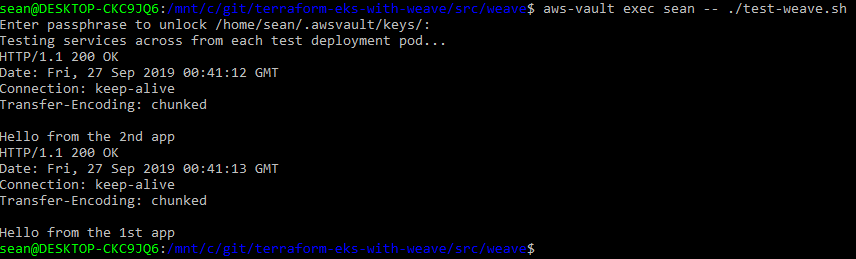
./setup-weave.sh
./test-weave.sh
Warning: This will create a new VPC, subnets, NAT Gateway instance, Internet Gateway, EKS Cluster, and set of worker node autoscale groups. So be sure Terraform Destroy this if you’re just testing things out.
– Your wallet
After terraform creates all the resources, you can run the two included shell scripts. setup-weave.sh will remove the AWS CNI, install CNI genie, Weave, and deploy two simple example pods and services.
At this point you should terminate your existing worker nodes (that still use the AWS CNI) and wait for your new worker nodes to join the cluster.
test-weave.sh will wait for the hello-node test pods to become ready, and then execute a curl command inside one, talking to the other via the the service and vice versa. If successful, you’ll see a HTTP 200 OK response from each service.
This is a quick post showing a nice and fast batch S3 bucket object deletion technique.
I recently had an S3 bucket that needed cleaning up. It had a few million objects in it. With path separating forward slashes this means there were around 5 million or so keys to iterate.
The goal was to delete every object that did not have a .zip file extension. Effectively I wanted to leave only the .zip file objects behind (of which there were only a few thousand), but get rid of all the other millions of objects.
My first attempt was straight forward and naive. Iterate every single key, check that it is not a .zip file, and delete it if not. However, every one of these iterations ended up being an HTTP request and this turned out to be a very slow process. Definitely not fast batch S3 bucket object deletion…
I fired up about 20 shells all iterating over objects and deleting like this but it still would have taken days.
I then stumbled upon a really cool technique on serverfault that you can use in two stages.
Iterate the bucket objects and stash all the keys in a file.
Iterate the lines in the file in batches of 1000 and call delete-objects on these – effectively deleting the objects in batches of 1000 (the maximum for 1 x delete request).
In-between stage 1 and stage 2 I just had to clean up the large text file of object keys to remove any of the lines that were .zip objects. For this process I used sublime text and a simple regex search and replace (replacing with an empty string to remove those lines).
So here is the process I used to delete everything in the bucket except the .zip objects. This took around 1-2 hours for the object key path collection and then the delete run.
Get all the object key paths
Note you will need to have Pipe Viewer installed first (pv). Pipe Viewer is a great little utility that you can place into any normal pipeline between two processes. It gives you a great little progress indicator to monitor progress in the shell.
Remove any object key paths you don’t want to delete
Open your all-the-stuff.keys file in Sublime or any other text editor with regex find and replace functionality.
The regex search for sublime text:
^.*.zip*\n
Find and replace all .zip object paths with the above regex string, replacing results with an empty string. Save the file when done. Make sure you use the correctly edited file for the following deletion phase!
Iterate all the object keys in batches and call delete
tails the large text file (mine was around 250MB) of object keys
passes this into pipe viewer for progress indication
translates (tr) all newline characters into a null character ‘\0’ (effectively every line ending)
chops these up into groups of 1000 and passes the 1000 x key paths as an argument with xargs to the aws s3api delete-object command. This delete command can be passed an Objects array parameter, which is where the 1000 object key paths are fed into.
finally quiet mode is disabled to show the result of the delete requests in the shell, but you can also set this to true to remove that output.
Effectively you end up calling aws s3api delete-object passing in 1000 objects to delete at a time.
This is how it can get through the work so quickly.
I’ve recently been doing a fair bit of automation work on bringing up AWS managed Kubernetes clusters using Terraform (with Packer for building out the worker group nodes). Read on for some handy tips on troubleshooting EKS worker nodes.
Some of my colleagues have not worked with EKS (or Kubernetes) much before and so I’ve also been sharing knowledge and helping others get up to speed. A colleague was having trouble with their newly provisioned personal test EKS cluster found that the kube-system / control plane related pods were not starting. I assisted with the troubleshooting process and found the following…
Upon diving into the logs of the kube-system related pods (dns, aws CNI, etc…) it was obvious that the pods were not being scheduled on the brand new cluster. The next obvious command to run was kubectl get nodes -o wide to take a look at the general state of the worker nodes.
Unsurprisingly there were no nodes in the cluster.
Troubleshooting worker nodes not joining the cluster
The first thing that comes to mind when you have worker nodes that are not joining the cluster on startup is to check the bootstrapping / startup scripts. In EKS’ case (and more specifically EC2) the worker nodes should be joining the cluster by running a couple of commands in the userdata script that the EC2 machines run on launch.
If you’re customising your worker nodes with your own custom AMI(s) then you’ll most likely be handling this userdata script logic yourself, and this is the first place to check.
The easiest way of checking userdata script failures on an EC2 instance is to simply get the cloud-init logs direct from the instance. Locate the EC2 machine in the console (or the instance-id inspect the logs for failures on the section that logs execution of your userdata script.
In the EC2 console: Right-click your EC2 instance -> Instance Settings -> Get System Log.
On the instance itself:
cat /var/log/cloud-init.log | more
cat /var/log/cloud-init-output.log | more
Upon finding the error you can then check (using intuition around the specific error message you found):
Have any changes been introduced lately that might have caused the breakage?
Has the base AMI that you’re building on top of changed?
Have any resources that you might be pulling into the base image builds been modified in any way?
These are the questions to ask and investigate first. You should be storing base image build scripts (packer for example) in version control / git, so check the recent git commits and image build logs first.